What to know
Introduction
The U.S. Centers for Disease Control and Prevention has hosted influenza forecasting challenges annually since the 2013-2014 influenza season, except for 2020-2021, when there was limited influenza activity. This report summarizes the performance of FluSight forecasts from the 2023-2024 U.S. influenza season. Further details on FluSight and the scoring methods can be found at the bottom of the page.
Results
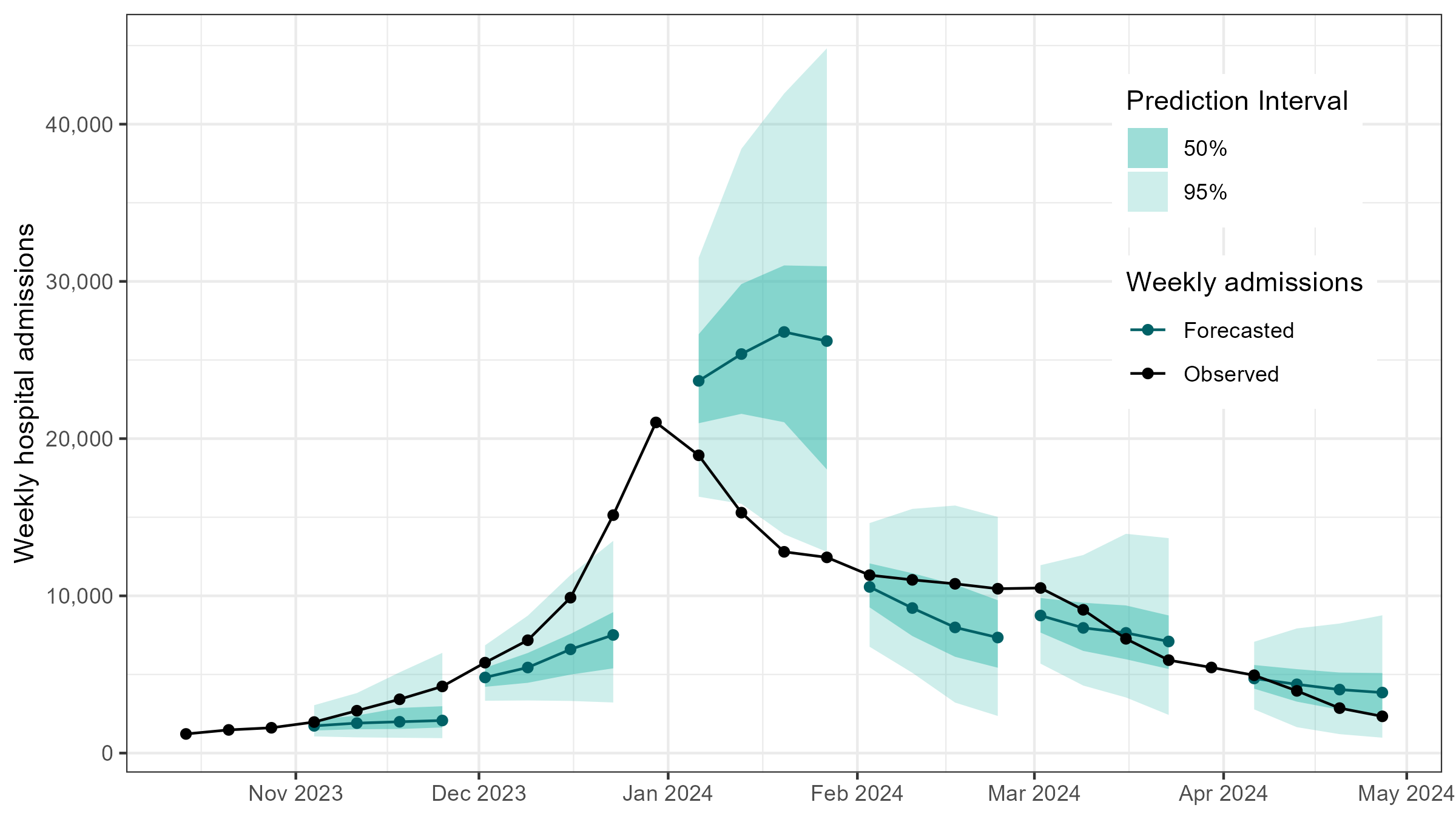
Influenza activity in the United States during the 2023-2024 season, which was a moderate severity flu season, was within the range seen during pre-COVID-19 seasons for both timing and intensity of activity. Influenza hospitalizations began to increase in early November, peaking nationally during the week ending December 30, 2023 (week 52), before declining slightly and remaining relatively stable at elevated levels through February 20241. The below figure shows national weekly observed influenza hospitalizations (black points) along with FluSight ensemble forecasts with 50% and 95% prediction intervals for six different submission timepoints during the 2023-2024 season (Figure 1). While ensemble forecasts, including the FluSight ensemble, have been among the most accurate for influenza forecasting efforts, they may not reliably predict rapid changes in disease trends, such as increases observed at the season onset and change at the peak. This pattern was seen during this season when the ensemble 50% prediction interval failed to capture the observed increase in November 2023 and decline in January 2024.
Figure 1: National Ensemble Forecasts
A total of 28 teams contributed forecasts from 36 unique models; of those, 28 models met inclusion criteria, were included in this analysis, and were categorized based on their methodologies as statistical, mechanistic, artificial intelligence or machine learning, or ensemble. A baseline model that carries forward the current value of hospitalizations was generated for comparison purposes. Forecasts were scored primarily using the relative weighted interval score (WIS), a forecast skill metric that measures how consistent a collection of forecast prediction intervals is with observed data. This metric is taken relative to the baseline model and should be interpreted as a value below 1 representing a forecast that was more accurate than the baseline. In terms of average relative WIS across the season, the FluSight ensemble, which is the model used by CDC to inform situational awareness and communicate forecast messaging, performed better than 27 of the 28 models. The only model that performed better was the UMass-flusion model2. The baseline model only performed better than nine contributed models (Table 1).
Table 1: Results for included models
Relative WIS values varied by jurisdiction. Table 2 shows how each model performed for each jurisdiction. The FluSight ensemble had the smallest range in relative WIS values across jurisdictions and performed better than the baseline in each jurisdiction. In general, more populous jurisdictions, like Texas and California, had lower relative WIS scores and less populous jurisdictions, like Alaska and Puerto Rico, had higher relative WIS scores.
Table 2: Relative WIS by jurisdiction and model
Forecasts were also scored on coverage, or how often the prediction interval contained the eventually observed value. Nine models, including the FluSight ensemble, had 95% coverage values greater than 90% which indicates that the forecast captured at least 90% of future observed values (Table 1 and Figure 2). The lowest coverage occurred on December 30, 2023, which aligns with the peak in hospital admissions (Figure 2). Models with high coverage values were often, but not always, the models with the lowest relative WIS scores.
Methods
CDC solicited weekly forecasts from academic, industry, and government forecasting teams from October 1, 2023, through May 1, 2024. The main forecasting target was weekly influenza hospital admissions for the current week and up to three weeks in the future for the United States, each state, Puerto Rico, and Washington DC. Target data, COVID-19 Reported Patient Impact and Hospital Capacity by State Timeseries, were downloaded from HealthData.gov and aggregated by week for each jurisdiction3. Final target data used for scoring were published May 3, 2024.
Each week, CDC created a baseline forecast (FluSight baseline) for comparison and an ensemble forecast (FluSight ensemble). The FluSight baseline model forecasted a median incidence equal to the last week with uncertainty based on observation noise. Methods for creating the baseline have been described previously4. The FluSight ensemble, which was used for CDC's influenza forecasting communications, is an ensemble that takes the median forecast from models designated for ensemble inclusion. It was created using the hubEnsembles R package5.
Prior to forecast submission, teams were required to submit model metadata which included information about methods, ensembling, and whether the model should be included in the FluSight ensemble6. Models were categorized based on model components including statistical (STAT), mechanistic (MECH), and artificial intelligence or machine learning (AI/ML). Components were determined based on submitted methods listed in the metadata. Teams were consulted to review model component characterization. Models with "mechanistic", "SEIR", "SIR", "SLIR", "km27", "compartment", "renewal", or "dynamics" in the description were considered to have mechanistic components, models that mentioned "lstm", "Bayesian", "random forest", "generative", "GRB", "SVM", "lightGBM", or had key words including "deep", "neural", or "machine learning" were considered to have AI/ML components, and methods that explicitly stated "statistical", "time-series", "ARIMA", "regression", "holt", or "random walk", or were not classified as having either mechanistic or AI/ML components were classified as having statistical components. Components were not considered mutually exclusive. Whether a model was an ensemble of other models was also included in categorization. Ensembles were explicitly reported by each team. This information was not used for scoring or analysis purposes but is included in Table 1 for reference.
For the analysis, we excluded models that submitted less than 75% of the total forecasts from all weeks and jurisdictions as well as national forecasts because of magnitude of admissions in the United States compared to states, and forecasts for Massachusetts from December 9, 2023, due to data quality concerns. Table 1 includes the percent of forecasts submitted.
Forecasts were evaluated on relative WIS using transformed counts with a natural logarithm to minimize the impact of count magnitude across jurisdictions7. WIS is a proper score that measures how consistent a collection of forecast prediction intervals is with log-transformed observed data. A lower value represents a better forecast. WIS is often calculated relative to the baseline to give relative WIS (<1 is better than the baseline). Relative WIS was calculated using the geometric mean WIS of each model forecast compared to the geometric mean WIS of the corresponding FluSight baseline model forecast7. Using the geometric mean allows for a more direct comparison of models even when not all models submit all or most forecast jurisdictions. This prevents penalization against models that may have submitted forecasts for all jurisdictions or jurisdictions that may be inherently more difficult to forecast.
Forecasts were also evaluated on 50% and 95% coverage. Coverage is a measure of how often the prediction interval captures the eventually observed values or the percentage of times a prediction interval correctly contains the observed value. WIS and coverage were calculated using the scoringutils R Package8.
All analyses were performed in R version 4.4.09.
- Influenza Division, C.f.D.C.a.P. Influenza Activity in the United States during the 2023–2024 Season and Composition of the 2024–2025 Influenza Vaccine. 2024; Available from: https://www.cdc.gov/flu/whats-new/flu-summary-2023-2024.html.
- Ray, E.L., et al., Flusion: Integrating multiple data sources for accurate influenza predictions. Epidemics, 2025. 50: p. 100810.
- COVID-19 Reported Patient Impact and Hospital Capacity by State Timeseries (RAW). Available from: https://healthdata.gov/Hospital/COVID-19-Reported-Patient-Impact-and-Hospital-Capa/g62h-syeh/about_data.
- Mathis, S.M., et al., Title evaluation of FluSight influenza forecasting in the 2021-22 and 2022-23 seasons with a new target laboratory-confirmed influenza hospitalizations. Nat Commun, 2024. 15(1): p. 6289.
- Krystalli, A., Ray, E.L., Shandross, L. hubEnsembles: Ensemble methods for combining hub model outputs. 2023; Available from: https://github.com/infectious-disease-modeling-hubs/hubEnsembles.
- Team, C.F. FluSight Forecast Hub. 2024; Available from: https://github.com/cdcepi/FluSight-forecast-hub.
- Bosse, N.I., et al., Scoring epidemiological forecasts on transformed scales. PLoS Comput Biol, 2023. 19(8): p. e1011393.
- Bosse, N., I., Gruson, H., Funk, S., Cori, A., van Leeuwen, E., Abbot, S., Evaluating Forecasts with scoringutils in R. 2022.
- Team, R.C. R: A Language and Envrionment for Statistical Computing. 2024; Available from: https://www.R-project.org/.